Demystifying Convex Functions
Proving Convexity of the MSE Loss Function
Testing the conditions for proving the convexity of mean squared error (MSE) function used in the context of Linear Regression.
- The previous blog — The Curious Case of Convex Functions, focused on laying the foundation for testing the convexity of a function. It enumerates different ways to test/prove the convexity of a function.
- In this article, we shall put that knowledge to use by proving the convexity of the Mean Squared Error loss function used in the context of Linear Regression.
With that in mind, let us start by reviewing -
- The MSE loss for a Regression Algorithm.
- Conditions for checking Convexity.
MSE Loss Function -
The MSE loss function in a Regression setting is defined as -


Checking for Convexity of J(w)-
For checking the convexity of the Mean-Squared-Error function, we shall perform the following checks -
- Computing the Hessian of J(w)
- Computing the Principal Minors of the Hessian.
- Based on the values of principal minors, determine the definiteness of Hessian.
- Comment on Convexity based on convexity tests.
Let us get down to it right away-
1. Computing the Hessian of J(w) -


2. Computing the Principal Minors -
From the previous blog post, we know that a function is convex if all the principal minors are greater than or equal to zero i.e. Δₖ ≥ 0 ∀ k
compute Δ₁ -
Principal Minors of order 1 (Δ₁) can be obtained by deleting any 3–1 = 2 rows and corresponding columns.
- By deleting row 2 and 3 along with corresponding columns Δ₁ = x₁²
- By deleting row 1 and 3 along with corresponding columns Δ₂ = x₂²
- By deleting row 1 and 2 along with corresponding columns Δ₃= x₃²
compute Δ₂ -
Principal Minors of order 2 can be obtained by deleting any 3–2 = 1 row and corresponding column.
- By deleting row 1 and corresponding column 1 -
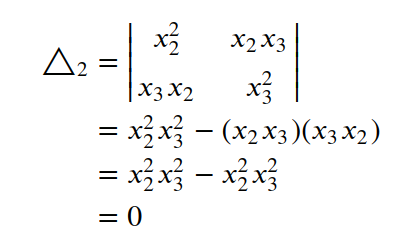
- By deleting row 2 and corresponding column 2
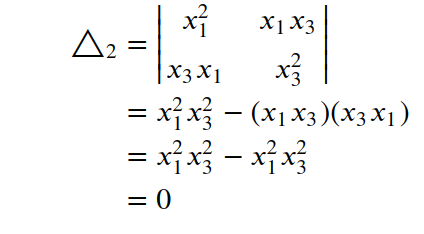
- By deleting row 3 and corresponding column 3
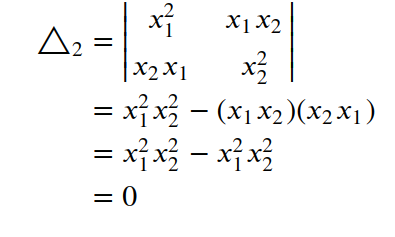
compute Δ₃ -
Principal Minors of order 3 can be obtained by computing the determinant of J(W).
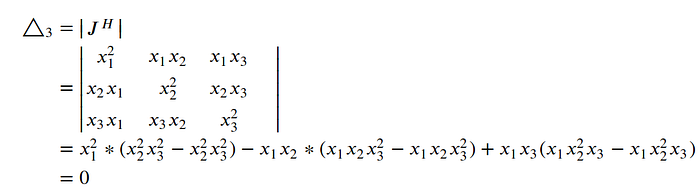
3. Comment on Definiteness of Hessian of J(w) -
- The principal minors of order 1 have a squared form. We know that a squared function is always positive.
- The principal minors of orders 2 and 3 are equal to zero.
- It can be concluded that Δₖ ≥ 0 ∀ k
- Hence the Hessian of J(w) is Positive Semidefinite (but not Positive Definite).
4. Comment on convexity -
Before we comment on the convexity of J(w), let’s revise the conditions for convexity -
If Xᴴ is the Hessian Matrix of f(x) then -
- f(x) is strictly convex in 𝑆 if Xᴴ is a Positive Definite Matrix.
- f(x) is convex in 𝑆 if Xᴴ is a Positive Semi-Definite Matrix.
- f(x) is strictly concave in 𝑆 if Xᴴ is a Negative Definite Matrix.
- f(x) is concave in 𝑆 if Xᴴ is a Negative Semi-Definite Matrix.
Since the Hessian of J(w) is Positive Semidefinite, it can be concluded that the function J(w) is convex.
Final Comments -
- This blog post is aimed at proving the convexity of MSE loss function in a Regression setting by simplifying the problem.
- There are different ways of proving convexity but I found this easiest to comprehend.
- It is important to note that MSE is convex on its inputs and parameters but it may not be convex when used in the context of a Neural Network given the non-linearities introduced by the activation functions.
- Feel free to try out the process for different loss functions that you may have encountered.
